Forced alignment(강제음성정열) 사용 방법
현재 개발 중입니다. 동일명의 wav 파일과 text 파일(예: test.wav, test.txt)을 올리지 않으면 system error가 발생할 수 있습니다.
wave 파일과 txt 파일의 예로 다음의 파일들을 다운받아 사용해 보시기 바랍니다.
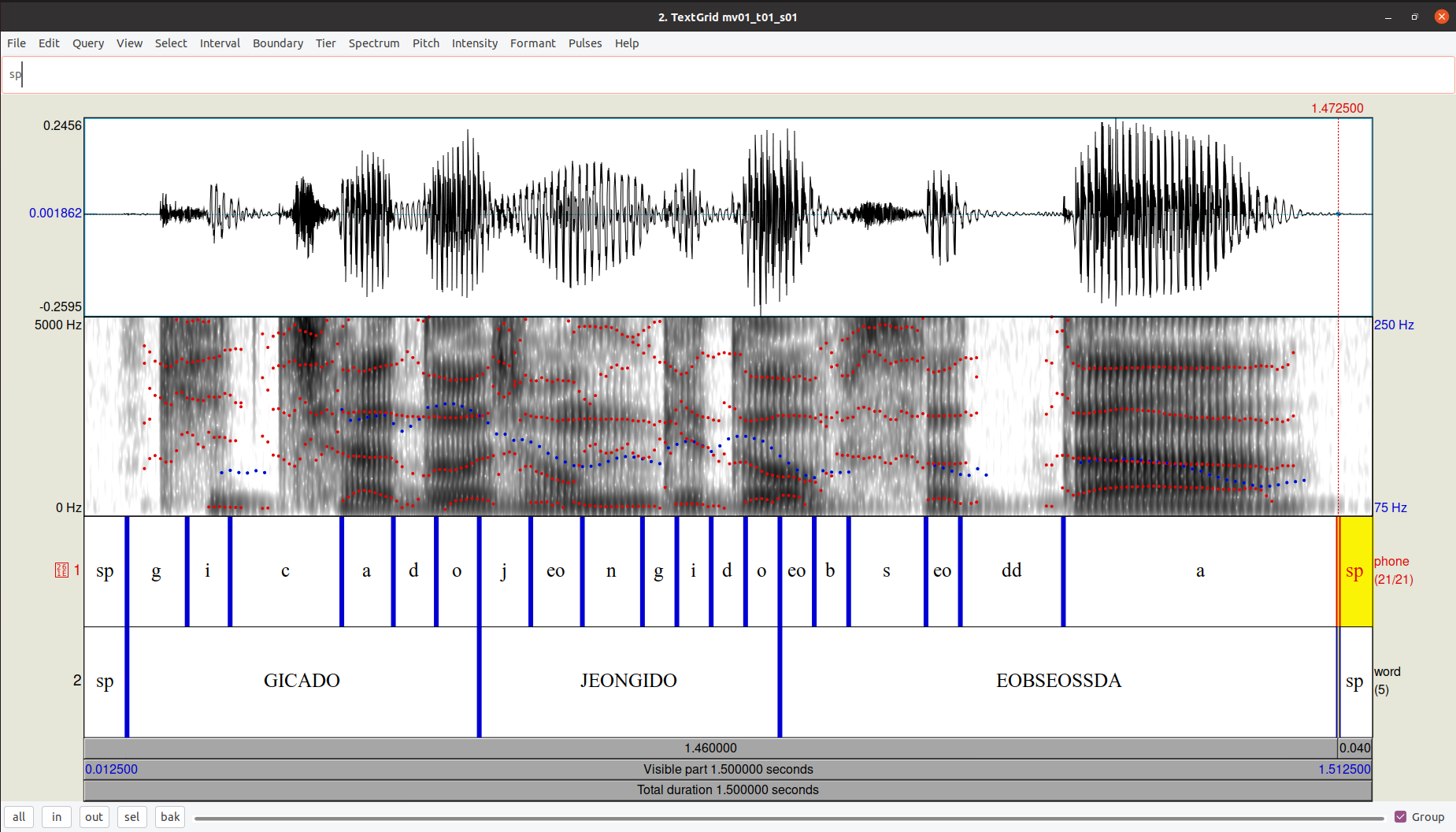
대체로 문장 단위로 녹음된 wav 파일과 한글로 받아 적은 txt 파일이 있으면, 소리 파일에서 단어 및 단어를 구성하는 자모음의 구간을 자동으로 포착해서 Praat의 TextGrid 형태로 반환해 줍니다. 100% 완벽하게 align되지는 않지만, manual correction을 통해 음성학 및 음운론 연구에 이용할 수 있습니다.
특징: 웹기반 시스템 중에 (아마) 유일하게 여러 파일들을 동시에 batch 처리할 수 있는 시스템입니다. 한꺼번에 64MB까지 처리가 가능하도록 설계되어 있습니다. 입력된 wav 파일은 16000Hz로 resampling됩니다. 한글 파일을 자동으로 romanize하고, 사전에 없는 단어들은 자동으로 사전에 첨가하여 OOV(out-of-vocabulary)가 없도록 forced align시킵니다.
성능을 최적화하기 위해서 한두문장으로 된 짧은 wave 파일과 동일한 파일명의 한글로 된 텍스트 파일을 업로드해 주기 바랍니다. wave 파일과 텍스파일을 한꺼번에 선택하여 upload할 수 있습니다. Upload 후 Download 페이지로 이동되고, Download 버턴을 누르면 result.zip 파일을 다운받게 됩니다. 강제정렬이 정상적으로 되었다면, 원래 올린 파일등 외에 (유니코드로 전환되) lab 파일(들)과 TextGrid 파일(들)을 result.zip 파일에서 확인할 수 있습니다. 올린 파일들은 서버에서 자동으로 삭제됩니다.
현재 개발 중입니다. 동일명의 wav 파일과 text 파일(예: test.wav, test.txt)을 올리지 않으면 system error가 발생할 수 있습니다.
wave 파일과 txt 파일의 예로 다음의 파일들을 다운받아 사용해 보시기 바랍니다.

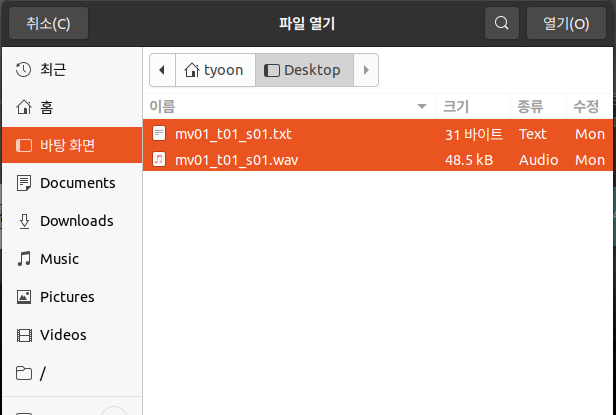
많은 파일을 한꺼번에 upload할 수는 있지만, 한 번 upload시킬 때 파일의 전체 크기가 64MB(44.1KHz로 녹음된 경우 약 6분 분량)가 넘지 않도록 하기 바랍니다. 대략 문장 단위로 저장된 파일들이 forced alignment의 오류를 수정하면서 연구하는 데 적절할 겁니다. 너무 긴 파일은 오류가 생기면 수정하기 힘듭니다.
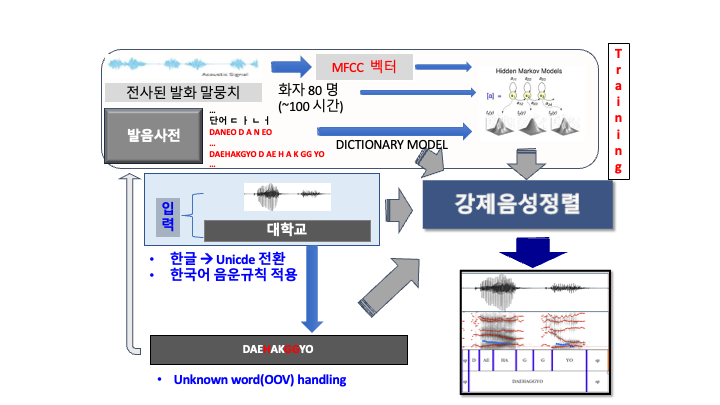
Automatic forced-alignment tools map wave forms to orthographic word or phone sequences. The web-based Korean forced alignment system can be used to force align wave files to romanized word and phone sequences, as shown in the example above.